Six Principles in Practice: How an Agentic E2E Found 11 Production Bugs in 8 Runs

Eight runs, eleven bugs
I ran my E2E testing system on a production ecommerce platform eight times in
a row – across five different business modules, in three different surface
configurations (admin / desktop storefront / mobile-first storefront). Across
those eight runs the system found eleven production bugs, each one
attached to a specific file and line via a root_cause_slug. Between runs
the knowledge base grew from 25 gotchas to 42 (+67% in nine days), and the
first-try pass rate (first_try_pass_rate) climbed from 14% to 95%.
One detail up front: the methodology was assembled in a side stream alongside product work, not as a dedicated project. Calibration cycles were interleaved between features, new-module sprints and routine support. Eight runs is not "eight weeks of full-time work" but eight iteration points accumulated in parallel with shipping production code. Most of that time I was writing business logic, not agents.
This isn't a story about "which framework to pick". Most teams start with E2E by asking exactly that question – and six months later they have a flaky suite that quietly gets disabled in CI. The right question is on what conditions these tests are entitled to exist at all, and what agent architecture lets them compound instead of accumulating noise.
This article is a closing piece for the previous publication Six Principles for Agent Systems That Don't Hallucinate. There I worked through the principles as an abstraction. Here – what happens when you apply them to a concrete task, in production, across two independent stacks.
Premise: six principles applied to E2E
E2E testing is a convenient test bed for agent systems for three reasons.
First, the validator is deterministic – the test either passes or it
doesn't, and there is no room for probabilistic judgment. Second, the cycle
is short – one run takes minutes, not hours or days. Third, the domain
gives an explicit signal when the system has "learned" the stack –
first_try_pass_rate plateaus.
All three properties are the same ones the Six Principles are built on in the general case: architecture over prompt-tweaking, deterministic context over probabilistic retrieval, closed-loop validation with a hard signal, three-category attribution, editorial gates instead of auto-promotion, multi-run measurement as proof of compounding.
If these principles work in the general case, then on E2E they should deliver a measurable effect. This essay is about the measured effect.
The contract: seven environment principles
E2E tests live or die by their relationship with the environment. Without an explicit contract, every flaky-test debate converges on the same question: is this a bug in the test, in the application, or in CI? – and no one can answer, because there is no shared baseline.
ENVIRONMENT.md is a markdown document with seven numbered principles.
Each is one paragraph plus a short why. Three audiences read it: a human
during onboarding, an LLM agent during test generation, and the test
runner (the last one via playwright.config.ts, not directly).
The principles in short:
- The container is an external dependency. Tests do not start or stop the application. If the instance is unavailable, the preflight check (principle 4) fails before any spec runs.
- The database is dirty by default. Demo data is reused across runs.
Test data is isolated via a prefix (
e2e_*), seeds are idempotent throughON CONFLICT DO NOTHING. - Sequential execution.
workers: 1,retries: 0,fullyParallel: false. This is not a performance compromise – it is a methodology commitment. Half of this principle – the no-retries doctrine – is the most load-bearing rule in the entire methodology. - Health check before everything.
global-setup.tsmakes one HEAD request to a health endpoint before any spec runs. Without the health check, the first failing test out of 50 produces an inscrutable timeout; with it, one clear error appears in five seconds. - Seed vs assertion separation. Seed specs configure state
(
tests/_seed/), assertion specs verify behavior (tests/modules/<feature>/). The underscore prefix is not stylistic; it is lexicographic sort order. - Host runner + MCP browser. Playwright runs on the host machine; during test generation the LLM agent has access to MCP browser tools – this lets it observe the real DOM rather than invent selectors.
- Session caching with TTL. Login is cached to a file; TTL depends on the backend's nature (admin session with DevMode login – 15 minutes; Redis session under a strict security policy – 2 minutes).
Each principle in depth lives in
contract-spec.md
in the principles repo.
The principles are deliberately minimal. The contract does not address test data factories (a structural question), selector strategy (a generator concern), or CI (orthogonal). The contract is the smallest explicit commitment that makes the rest of the methodology coherent. Extending the contract is fine; expecting the contract to cover everything is a category error.
Four layers of code
The contract says what tests do and don't do. The structure says where the artifacts of doing those things physically live. Four layers, with strict one-way dependency direction:
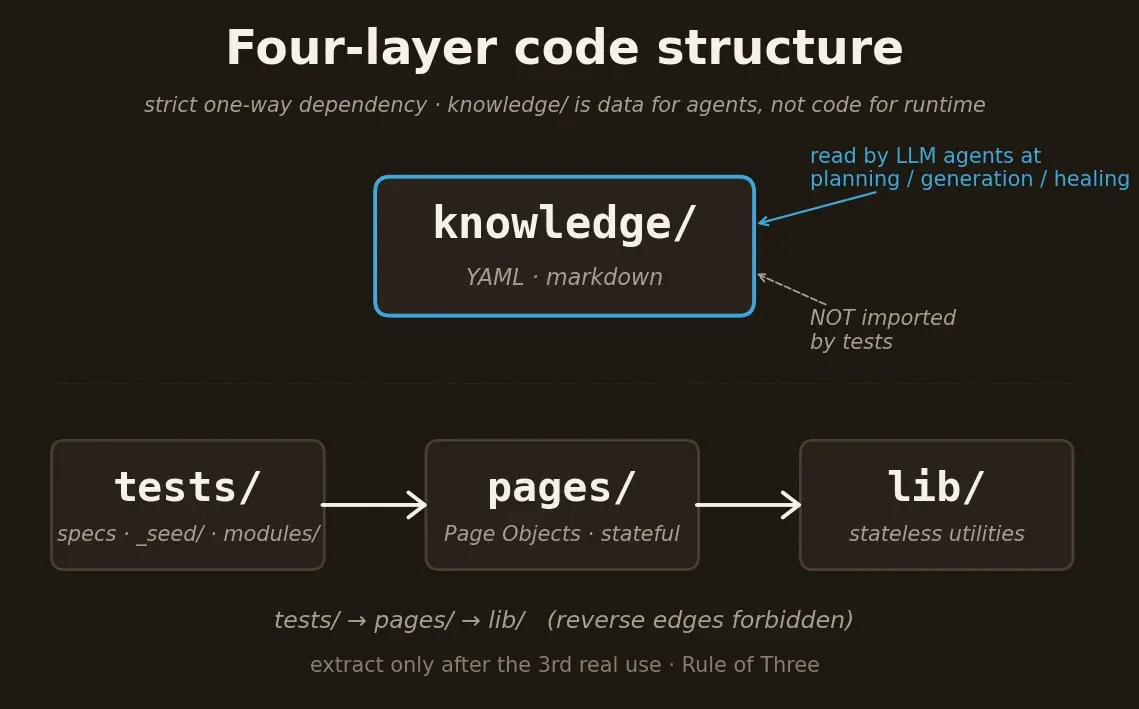
lib/– stateless utilities. If a function inlib/is calledsetupCheckoutTaxForRegion, it doesn't belong inlib/– it belongs in a Page Object or a flow.pages/– Page Objects. Stateful. Extracted only after the third real use (Rule of Three).tests/– the specs themselves._seed/(idempotent setup) andmodules/<feature>/(per-feature assertions).knowledge/– markdown/YAML references for LLM agents. Never imported by tests. This is data for agents, not code for the runtime.
The tests → pages → lib direction is one-way. Reverse edges are
forbidden. Empirically: across four cross-stack ports, every cycle of
"lib imports from pages" had to be reverted within the same sprint. The
cost of portability with a cycle in place is too high.
The most common objection is "extract pages/ from day one?". No. Rule
of Three: one test – leave it inline; two – leave them duplicated;
the third – extract into lib/ (stateless) or pages/ (stateful).
At two uses you don't yet see what is actually shared. The third use
shows the real abstraction instead of a coincidental match between two
cases.
A single playwright.config.ts serves several orthogonal surface
combinations – not "different browsers" but different DOMs. On my
ecommerce platform: admin / classic storefront (legacy MVC) / modern
storefront (Alpine.js). Different DOM, different selectors, the same
behavior cases. One run produces three results with a per-project
breakdown in metrics.jsonl.
The four-agent pipeline
The pipeline runs four agents in sequence: analyze → plan → generate → heal. Each agent has one cognitive task, one input shape, one output shape.
Analyzer
The first. Discovery: scans the codebase, identifies modules, routes,
DB schema, dependencies. Writes results into e2e/.state/*.json –
persistent JSON artifacts. The phase is cheap and cacheable – on
every run it first checks the mtime of its outputs; if they are fresh,
it skips entirely.
The skip logic here is not optimization, it is architecture. Most cycles
work on a stable codebase; re-scanning the source tree every time is
waste. The analyzer's artifacts (modules.json, schema-map.json,
project-auth.yml, project-seed.yml) are read by the planner,
generator and healer – each takes what it needs, no one re-runs
discovery.
Planner
The second. Reasoning: takes the analyzer's output plus the KB, writes
a plan.md – a numbered list of test cases for one feature. Each case:
short title, preconditions, steps, expected outcome, optional KB
references to relevant gotchas.
The planner is a distinct phase, not a step inside the generator, because planning and code-generation are different cognitive modes. Planning needs broad context (feature semantics, edge cases, KB flags). Generation needs narrow context (the exact selector for one button on one page). Trying to do both in one prompt produces either an over-prompted generator (slow, expensive) or an under-prompted planner (shallow plans, missed edge cases).
plan.md is not test code. It is a specification that the generator
turns into code in the next phase. The same plan.md could be
implemented in a different test framework.
Generator
The third. Code emission: takes plan.md and writes *.spec.ts. The
defining rule is selector discipline: every selector that appears in
a generated spec must be observed in the live application via MCP
browser tools – not inferred from sources, not guessed from a
screenshot.
What "stable selector" means depends on the surface. For each project
the generator has a preference hierarchy: getByRole(...) →
getByPlaceholder(...) → scoped CSS → id – in descending order of
stability.
What is forbidden: deriving a selector from source code (the
rendered DOM may differ); guessing from a screenshot; "the button
probably has the class .btn-primary". If a stable selector doesn't
exist, the correct reaction is to report a gap back to the planner,
not to write something brittle and hope.
Healer
The fourth, and the most important. Diagnosis: runs the specs, observes
failures, attributes each failure to one of three categories –
test-bug / app-bug / env-drift – and writes a structured
heal-finding with the audit trail.
That attribution is what makes the no-retries doctrine actionable. Each category has its own remediation path:
test-bug→ the healer fixes the spec.app-bug→ the healer does not fix the application. It files the bug withroot_cause_slugand leaves the spec failing as a true positive.env-drift→ the healer surfaces the drift; the contract may need updating.
The healer is also the agent that proposes KB candidates. A failure
exposed a gotcha future tests should know? The healer writes a candidate
into e2e/knowledge/_inbox/. The candidate is not auto-promoted –
an editorial gate decides.
Why four agents, not three
Early versions of the methodology used three agents (planner /
generator / healer) and folded discovery into the planner. The
four-agent split was empirical: a planner prompt that also did
discovery was noticeably worse at both jobs. Pulling the analyzer into
its own phase made each phase smaller, cheaper, and individually
skippable (analyzer caches; planner skips when plan.md exists;
healer skips on a green run).
The pipeline produces measurable artifacts at every boundary:
e2e/.state/*.json after analysis, plan.md after planning,
*.spec.ts after generation, a six-section heal-finding after healing.
Each is reviewable. Each is comparable across runs.
Per-agent depth lives in the four agent-role specs in the principles
repo. Skill-level orchestration lives in
skill-design.md.
Knowledge as the fourth layer
The knowledge base is the fourth layer of the structure and the input that makes agents learn between runs. KB files are YAML documents, read by agents at planning, generation and healing time. They are never imported by test code.
Two categories of entry
Every KB entry is one of two kinds:
- Gotcha – prose advisory for the agent. "When clicking a button inside a modal on the admin surface, wait for the loading-mask overlay to disappear". Gotchas are advisory; the agent reads them as context, not as an enforceable rule.
- Lint pattern – a machine-checkable rule with a severity. "If a
spec calls
page.click()on.btn-primarywithout precedingwaitForLoadingMask()– warning". Lint patterns are runnable as a static analysis pass (--phase lint).
An entry starts as a gotcha. Promotion to a lint pattern is downstream and explicit, after the gotcha has fired enough times for the rule to clearly generalize.
Project-local vs cross-stack
The KB has two homes. Project-local lives inside e2e/knowledge/ –
about this codebase: auth patterns, seed fixtures, business-domain
quirks. Cross-stack lives outside any single project (for example,
in ~/.claude/skills/e2e-kb/kb/) – about a technology: UI framework
patterns, Tailwind class quirks, admin framework selectors. Cross-stack
KB generalizes across every project that uses the same technology.
This split is what produces cross-project knowledge transfer. When you start a new project on a familiar technology, cross-stack KB applies on day one. Project-local KB starts empty and fills as the codebase reveals its quirks.
sources.yml routing and kb_by_app
sources.yml describes which KBs apply to which surface:
universal:
- project-auth.yml
- project-seed.yml
by_surface:
admin:
- modules/admin.yml
- platform/admin-framework.yml
storefront:
- modules/storefront.yml
- platform/alpine-js.yml
- platform/tailwind-css.yml
The planner reads sources.yml and loads only the KBs relevant to the
target.
For multi-app projects – one repository hosting two genuinely different
application stacks (a FastAPI backend and a Next.js admin in the same
work tree) – the pattern extends to kb_by_app:
kb_by_app:
backend:
- platform/fastapi.yml
- platform/alpine-js.yml
- platform/tailwind-css.yml
- project-auth.yml
admin-app:
- platform/nextjs.yml
- platform/shadcn-ui.yml
- platform/tailwind-css.yml
- project-auth.yml
Tests for the backend receive fastapi + alpine-js KB; tests for the
admin receive nextjs + shadcn-ui. No cross-contamination, no agents
loading irrelevant gotchas. The same tailwind-css.yml is reused in
both apps – cross-project KB reuse on a small scale.
Editorial promotion
The single most important rule of the KB layer:
Auto-promotion of healer candidates into the active KB is forbidden.
Auto-promotion optimizes recall at the expense of precision. The resulting KB describes the system's errors, not what is true. The agent then retrieves contradictory advice (every fix has become a "principle"), and compounding flips sign – the saturation curve moves downward instead of upward.
Promotion is editorial: the healer writes a candidate into _inbox/;
a reviewer asks two questions (does this generalize? is it not covered
by an existing entry?); only on two yeses does the candidate move
into the active KB. The editorial gate is what keeps the KB useful
as the project grows.
The healing loop and the saturation curve
The healer produces one artifact per run: a markdown file in
e2e/.state/heal-findings/, timestamped. Six sections, always in the
same order, even on green runs.
The six sections are not bureaucracy. They are an audit trail that stays readable two months later:
- A. Diagnosis matrix – a table: tests × projects. Pass / Fail / Skip / N/A in cells. The reviewer sees it first – "what failed and where" before any narrative.
- B. Hypothesis on root causes – for each failure, a working theory. Each hypothesis names an attribution category.
- C. Healing action + decision rationale – what the healer did.
test-bugis fixed in the spec,app-bugis filed with a slug,env-driftis surfaced. - D. Verification checklist – how to confirm the fix worked. A checklist, not prose. This is what makes the audit trail closeable.
- E. KB candidates – gotchas worth promoting (via the editorial gate).
- F. Out-of-scope siblings – observations that surfaced during the run but are not the focus of this finding. Test-infra glitches, environment quirks, remarks worth follow-up but no action right now.
Section F matters separately: without it, observations either clutter the main narrative (A–E) or get lost and rediscovered a month later as "haven't we seen this already?".
Why this produces compounding
Every heal-finding's Section E feeds the _inbox/. The editorial gate
either promotes or rejects. Promoted entries become available to the
next run's planner and generator. The next run on the same surface
starts with a richer KB, and first_try_pass_rate rises.
That is the compounding mechanism. It depends on three preconditions:
- Three-category attribution (the no-retries doctrine) – without it, failures become "flaky", and the healer has nothing structured to record.
- Editorial promotion – without it, the KB becomes an error log, and the curve flips sign.
- Per-run findings (the six-section discipline) – without them, the audit trail is missing, and the next reviewer can't follow the chain.
The saturation curve
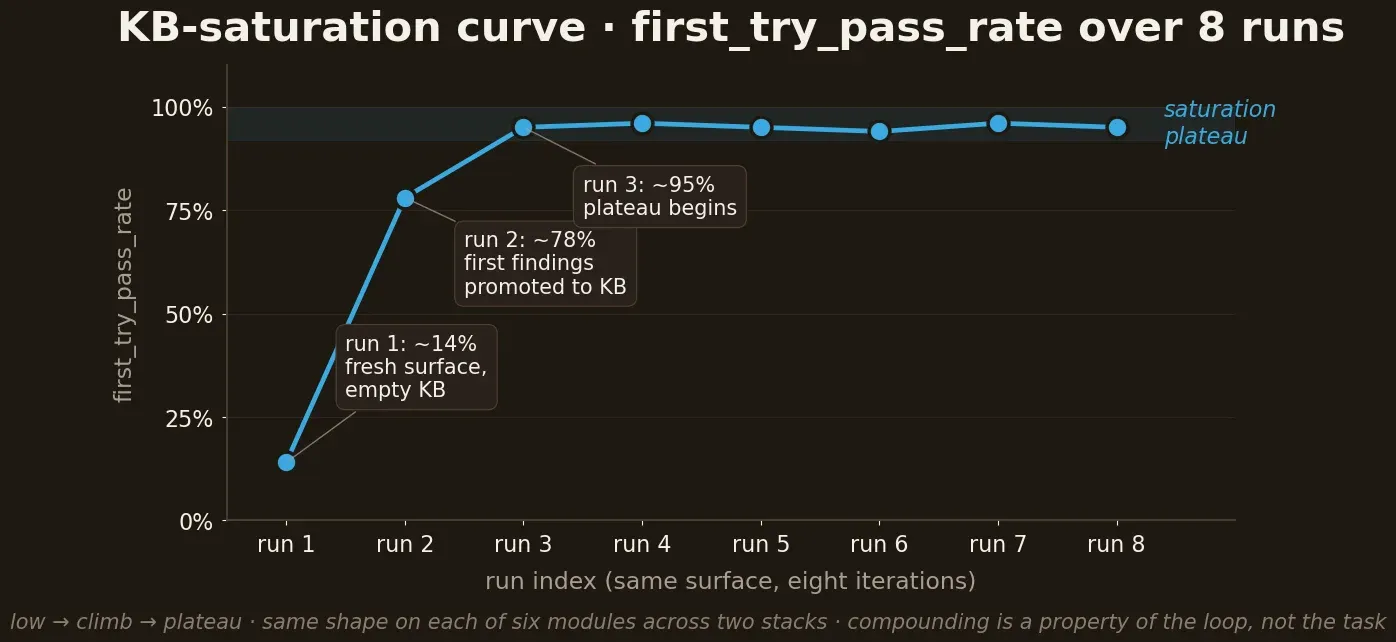
Run 1: low pass rate. Every gotcha is new; the KB is empty for the surface.
Runs 2–3: rate climbs steeply, as the first findings get promoted into the KB. The agent now reads gotchas it discovered itself last time.
Runs 4+: rate plateaus. The KB has captured the surface's idiosyncrasies; further runs only encounter rare new gotchas.
The plateau is saturation. The empirical signal that the methodology has paid for itself on this surface. After saturation the cost of a new test on the surface is dominated by defining the case, not learning the surface.
Across my eight runs: on a mature module (third run on the same
surface) first_try_pass_rate reached ~95%. On a new surface of the
same platform – first run ~14%, second ~78%, third ~95%. The same
shape on each of six modules: low → climb → plateau. This isn't a
theoretical benefit – it is measured.
What the metrics don't track
- Test execution time. Playwright's reporter handles that.
metrics.jsonlis about the quality of generated tests, not their runtime. - Code coverage in the line-coverage sense. That is a different methodology (instrument, run, report).
- Subjective quality. "Are these tests good?" is a review question, not a metric. The metric measures whether they pass.
The full metrics.jsonl schema with the additive evolution v1 → v2,
the definition of first_try_pass_rate, the root_cause_slug
discipline – all in
metric-design.md.
Stack-agnostic: porting to FastAPI in days, not weeks
The strongest objection to any "works for me" methodology is it works only because you know your stack. I ported the methodology to a second stack – not on a new machine and not for an article, but for my own pet project: FastAPI + Alpine (backend) + Next.js (admin) in a single work tree. The port took days, not weeks.
What carries over 1-to-1
- The four agents (analyze / plan / generate / heal) – same prompts, same contract between phases.
- The
e2e-coverageskill – same orchestrator, same artifact on output (ametrics.jsonlline, a heal-finding). - The
ENVIRONMENT.mdpattern – 7 principles stayed. Some are trivially satisfied (no auth → principle 7 N/A), but the contract kept its shape. - STRUCTURE.md – four layers, Rule of Three, dependency direction.
- No-retries doctrine –
retries: 0on the new stack.
What is rewritten
knowledge/– local gotchas (FastAPI middleware quirks instead of legacy MVC). Cross-stack KB (alpine-js.yml,tailwind-css.yml) is reused without change.lib/– FastAPI auth helpers instead of platform CLI calls.playwright.config.ts– different projects (backend+admin-appinstead ofadmin+classic-storefront+modern-storefront).
What appeared new on the second stack
kb_by_approuting – a solution to the multi-app problem (onee2e/serving two genuinely different app stacks). The pattern then back-ports onto the first stack if a multi-app scenario emerges.
Metrics on the second stack
First run on the new backend: first_try_pass_rate ~48.6%. Second –
~91.4%. Same two-to-three runs of the same surface, the same
compounding shape.
What matters: the second stack didn't "repeat" the first. It showed that the shape of the curve is a property of the loop, not of the task. Detect a deterministic validator (tests pass/fail, build succeeds, types check), close the loop (executor → validator, auto-revert on regression, KB grows only on validated new error classes) – and compounding appears regardless of stack.
After the cross-platform port I have n=2 platforms plus n=8 runs within the first. The KB saturation curve is not a Magento artifact. It is a property of the pipeline.
Closing
The six principles from the meta article are not dogma. They are a set of architectural commitments that will make an agent system compound, if you accept them. This article showed what happens on a concrete task – E2E testing – when you accept them in full.
What is useful here beyond "another E2E framework":
- Structural framing of the flaky-test problem. Not "which runner to buy", but what conditions must be met for tests to exist as a signal rather than as noise. Those conditions are expressed in the seven contract principles.
- Compounding proved through measurement. The KB saturation curve is not theoretical. It appears on two independent stacks, in the same shape. Single-run anecdotes really are almost useless for evaluating an architecture; the multi-run curve is a different story.
- Editorial gates as load-bearing. Auto-promotion is the most obvious step that breaks compounding. That is counter-intuitive and worth surfacing explicitly.
If you want to apply the methodology – the principles repo with granular specs and illustrative examples (against todomvc as a neutral target): https://github.com/webmaster-ramos/e2e-llm-agents.
The canonical narrative with principles and architecture lives on the
site at /docs/e2e-llm-agents:
https://webmaster-ramos.com/docs/e2e-llm-agents.
The meta article with the six principles as an abstraction: https://webmaster-ramos.com/blog/six-principles-agent-systems.
Comments
No comments yet. Be the first to share your thoughts.
Sign in to leave a comment. Only registered readers can comment.